Stencil Buffer, Stencil Test и Task Stealing для CUDA
Введение
Stencil buffer или буфер трафарета обычно используется в графике (OpenGL, DirectX) для того, чтобы замаскировать некоторые пикселы на изображении вызовы пиксельного шейдера для некоторых областей изображения. В тексте специально подчеркнуто, что stencil test производится еще до вызова пиксельного шейдера и, таким образом, в тех местах где изображение отсутствует, пиксельный шейдер вообще не будет вызываться и никакая лишняя работа выполняться не будет.
Физически, стенсил хранится на GPU в том же буфере, где хранится глубина и бывает разного формата. Например, наиболее широко используемый формат D3DFMT_D24S8 означает, что 24 бита отводятся в бэк-буфере на глубину и 8 бит на стенсил. В данной статье, мы будет использовать упрощение и считать, что стенсил-буфер хранит на каждый пиксел (или на поток) всего один бит. Если бит равен 1, то пиксел (поток) активен. Если 0, то неактивен. Это позволит сэкономить немного памяти и упростит изложение.
Stencil Test часто используют для построения отражений таким методом:

Рисунок 1. Stencil buffer нужен для маскирования отражений в тех местах где их на самом деле нет (как на рис. справа).
-
1. Очищаем стенсил-буфер нулями.
-
2. Включаем запись в стенсил буфер и рисуем в него плоскость, относительно которой будем считать отражение. Записываем всегда единичку. Получается, что в буфере маски хранится бинарное изображение нашего зеркала (то есть там где есть зеркало будут храниться единицы, а там где зеркала нет - нули).
-
3. Отражаем всю геометрию относительно плоскости при помощи специальной матрицы, и рисуем ее, включая стенсил-тест. Таким образом, там где на изображении находилось зеркало, будет выведено отражение. А там где его нет, ничего не изменится.
Собственно цвет зеркала и объекта удобно комбинировать при помощи пиксельного шейдера (ну можно при помощи альфа блендинга, если видеокарта совсем старая).
Программная реализация на CUDA
К сожалению, в куде, как и во всех остальных ‘compute’ технологиях (DX11 CS, OpenCL) механизм стенсил-теста просто отсутствует. В то же время, это вещь очень полезная, особенно если ваши вычисления реализованы в виде длинного конвейера из нескольких (часто довольно небольших) ядер (kernels). Допустим у вас имеется N потоков.
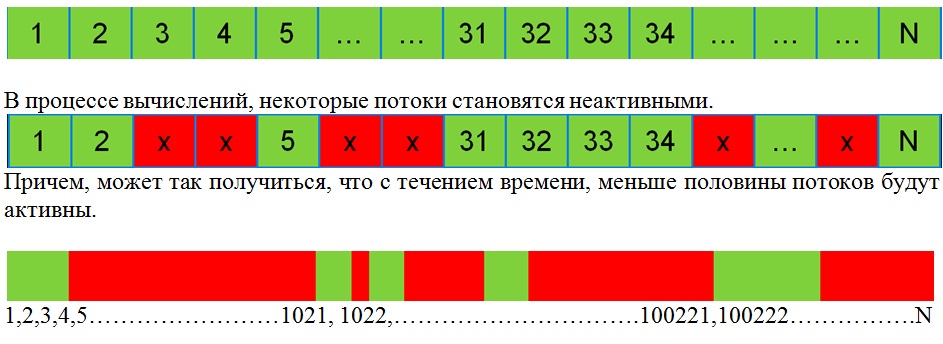
Например, такая ситуация встречается при реализации на куде трассировки лучей. При глубине переотражений около 5, на некоторых сценах, меньше 10 % потоков будет активны на последнем уровне.
Для того, чтобы не выполнять работу для неактивных потоков вы, скорее всего, заведёте флаг в каком-нибудь буфере и будете проверять, если это флаг равен 0, то ничего не делать.
uint activeFlag = a_flags[tid];
if(activeFlag==0)
return;
Это решение в принципе работает, но оно имеет 2 недостатка. Первое – чрезмерная трата памяти (N потоков*sizeof(dataWithFlag)). Второе – кернел будет гонять данные 'dataWithFlag' по шине. Это плохо в том случае, если желательно быстро терминировать ничего не делающие потоки, потому что латентность памяти довольно значительная а каждый поток будет гарантированно читать свой флаг, так что кэш здесь не поможет.
В данной статье предлагается хранить в стенсил-буфере на 1 поток всего один бит и избежать массовых трансфертов данных по шине (или по крайней мере значительно их сократить, эффективно используя кэш).
Детали реализации
Итак, заводим стенсил буфер размером ровно на (N/32)*sizeof(int) байт. И привязываем к нему текстуру.
cudaMalloc((void**)&m_stencilBuffer, N*sizeof(int)/32);
cudaBindTexture(0, stencil_tex, m_stencilBuffer, N*sizeof(int)/32);
Сама текстура объявлена в каком-нибудь хедере (.h файл) следующим образом:
Texture<int, 1, cudaReadModeElementType> stencil_tex;
Далее, в том же файле объявим такой вспомогательный массив:
static __device__ int g_stencilMask[32] = {
0x00000001, 0x00000002, 0x00000004, 0x00000008, 0x00000010, 0x00000020, 0x00000040, 0x00000080,
0x00000100, 0x00000200, 0x00000400, 0x00000800, 0x00001000, 0x00002000, 0x00004000, 0x00008000,
0x00010000, 0x00020000, 0x00040000, 0x00080000, 0x00100000, 0x00200000, 0x00400000, 0x00800000,
0x01000000, 0x02000000, 0x04000000, 0x08000000, 0x10000000, 0x20000000, 0x40000000, 0x80000000
};
В этом массиве хранятся маски, с которыми мы будем делать логический & для того, чтобы быстро получить нужный потоку бит. То есть получить ровно тот бит, номер которого равен номеру потока внутри warp-а. Вот как будет выглядеть stencil test:
#define STENCIL_TEST(tid) \
if(!(tex1Dfetch(stencil_tex, (tid) >> 5) & g_stencilMask[(tid)&0x1f])) \
return;
Для тех кернелов, которые только читают стенсил буфер, применять макрос следует в начале кернела следующим образом:
__global__ void my_kernel(…)
{
uint tid = blockDim.x * blockIdx.x + threadIdx.x;
STENCIL_TEST(tid);
// my code here
//
…
}
На практике (GTX560) такой стенсил тест примерно на 20-25% быстрее, чем простая проверка проверка вида:
uint activeFlag = a_flags[tid];
if(activeFlag==0)
return;
Однако, с учетом экономии памяти, профит определенно есть. Следует так же отметить, что на видеокартах с менее широкой шиной (например GTS450) ускорение может быть более существенным.
Итак, осталось реализовать лишь запись в стенсил-буфер. Сначала читаем значение для всего в warp-а из стелсил-буфера в переменную activeWarp; Затем каждый поток получает из этой переменной свой бит при помощи логического & и хранит его в переменной active. В конце кернела мы соберем из всех переменных active для данного warp-а значения обратно в один 32 разрядный uint, и нулевой поток warp-а запишет результат назад в память.
// (tid >> 5) same as (tid/32)
// (tid & 0x1f) same as (tid%32)
//
__global__ void my_kernel2(…,uint* a_stencilBuffer)
{
uint tid = blockDim.x * blockIdx.x + threadIdx.x;
uint activeWarp = a_stencilBuffer[tid >> 5];
if(activeWarp==0) // all threads in warp inactive
return;
// each threads will store it's particular bit from group of 32 threads
uint active = activeWarp & g_stencilMask[tid&0x1f];
if(!active)
goto WRITE_BACK_STENCIL_DATA;
// my code here
//
…
WRITE_BACK_STENCIL_DATA:
WriteStencilBit(tid, a_stencilBuffer, active);
}
Если поток неактивен, он сразу перейдет в конек кернела. Если по какой-либо причине вы внутри вашего кода решили, что этот поток должен быть неактивен, сделайте так:
if(want to kill thread)
{
active = 0;
goto WRITE_BACK_STENCIL_DATA;
}
В примере намеренно использована метка и оператор goto. Хоть это и является плохим стилем программирования, в данном случае это добавляет безопасности вашему коду. Дело в том, что вы обязаны гарантированно достичь кода функции WriteStencilBit. Если по какой-то причине внутри вашего кода вы решите сделать return, всё поломается (чуть позже обсудим почему). Вместо return надо ставить goto WRITE_BACK_STENCIL_DATA, чтобы перед выходом, все потоки из warp-a могли собрать данные, а нулевой поток (нулевой внутри warp-a) запишет их в стенсил-буфер. Собственно, функция WriteStencilBit выглядит следующим образом:
__device__ void WriteStencilBit(int tid, uint* a_stencilBuffer, uint value)
{
uint stencilMask = __ballot(value);
if((tid & 0x1f) == 0) // same as tid%32 == 0
a_stencilBuffer[tid >> 5] = stencilMask;
}
Функция __ballot() возвращает uint, где каждый i-ый бит равен 1 тогда и только тогда, когда то, что находится в ее аргументе не равно нулю. То есть она делает в точности то, что там нужно, сшивая обратно в uint флаги от разных потоков внутри warp-а.
Функция __ballot() принадлежит к так называемым “warp vote functions” и работает очень быстро. К сожалению, она доступна только для compute capability 2.0, то есть видеокарт с архитектурой Fermi. Важное замечание по её работе, следующий код будет неправильным:
__device__ void WriteWrongStencilBit(int tid, uint* a_stencilBuffer, uint value)
{
if((tid & 0x1f) == 0) // same as tid%32 == 0
a_stencilBuffer[tid >> 5] = __ballot(value);
}
Дело в том, что __ballot() будет всегда помещать 0 в те биты, чьи потоки замаскированы в данный момент. А все потоки с номером внутри варпа не равным нулю (1..31) будут замаскированны и не попадут внутрь оператора if, поэтому 1..31 биты результата функции __ballot() для такого кода всегда будут равны нулю. Отсюда правда следует интересный вывод. Если вы гарантированно пишете для видеокарт с архитектурой Fermi, то даже для кернелов которые пишут в стенсил буфе, вы можете убивать поток следующим образом:
if(want to kill thread)
return;
Таким образом, потоки, для которых вы сделали return будут замаскированы и __ballot() вернет в своем результате нули для соответствующих бит. Есть правда одна тонкость. По крайней мере для нулевого потока внутри warp-а вы так сделать не можете, иначе результат просто не запишется назад. Поэтому на самом деле можно делать только так
if(want to kill thread && (tid&0x1f!=0))
return;
Или пользуйтесь формой предложенной выше:
if(want to kill thread)
{
active = 0;
goto WRITE_BACK_STENCIL_DATA;
}
Особенности реализации для старой аппаратуры (G80-GT200)
Рассмотрим теперь, какие расширения должны быть сделаны, чтобы стенсил эффективно работал и на более старых GPU. На этих видеокартах не поддерживается функция __ballot(). Перепишем функцию WriteStencilBit в соответствие с теми возможностями, которые у нас имеются:
template<int CURR_BLOCK_SIZE>
__device__ inline void WriteStencilBit(int tid, uint* a_stencilBuffer, uint value)
{
#if COMPUTE_CAPABILITY >= COMPUTE_CAPABILITY_GF100
uint stencilMask = __ballot(value);
if((tid & 0x1f) == 0)
a_stencilBuffer[tid >> 5] = stencilMask;
#elif COMPUTE_CAPABILITY >= COMPUTE_CAPABILITY_GT200
if(__all(value==0))
{
if((tid & 0x1f) == 0)
a_stencilBuffer[tid >> 5] = 0;
}
else if(__all(value))
{
if((tid & 0x1f) == 0)
a_stencilBuffer[tid >> 5] = 0xffffffff;
}
else
{
__shared__ uint active_threads[CURR_BLOCK_SIZE/32];
uint* pAddr = active_threads + (threadIdx.x >> 5);
if((tid & 0x1f) == 0)
*pAddr = 0;
atomicOr(pAddr, value);
if((tid & 0x1f) == 0)
a_stencilBuffer[tid >> 5] = *pAddr;
}
#else
__shared__ uint active_threads[CURR_BLOCK_SIZE];
active_threads[threadIdx.x] = value;
if((threadIdx.x & 0x1) == 0)
active_threads[threadIdx.x] = value | active_threads[threadIdx.x+1];
if((threadIdx.x & 0x3) == 0)
active_threads[threadIdx.x] = active_threads[threadIdx.x] | active_threads[threadIdx.x+2];
if((threadIdx.x & 0x7) == 0)
active_threads[threadIdx.x] = active_threads[threadIdx.x] | active_threads[threadIdx.x+4];
if((threadIdx.x & 0xf) == 0)
active_threads[threadIdx.x] = active_threads[threadIdx.x] | active_threads[threadIdx.x+8];
if((threadIdx.x & 0x1f) == 0)
active_threads[threadIdx.x] = active_threads[threadIdx.x] | active_threads[threadIdx.x+16];
uint* perWarpArray = active_threads + ((threadIdx.x >> 5) << 5);
if((tid & 0x1f) == 0)
a_stencilBuffer[tid >> 5] = perWarpArray[0];
#endif
}
Таким образом, если у нас GT200 мы можем делать атомики в шаред-память + доступны 2 функции голосования, __any и __all, так что мы их можем использовать. Ну а если это G80 то остается только классическая редукция.
Так как на G80-GT200 обращения в глобальную память не кэшируются, то STENCIL_TEST лучше переписать без использования таблицы масок:
#define STENCIL_TEST(tid) \
if(!(tex1Dfetch(stencil_tex, (tid) >> 5) & (1 << ((tid)&0x1f) ))) \
return;
Persistent threads (task stealing на CUDA)
Раз уж мы затронули тему распределения работы, нельзя не упомянуть о таком важном трюке как persistent threads. Итак, вернемся к рисункам с замаскированными потоками.

Что происходит в железе, когда вы убиваете потоки некоторым случайным образом, и среди массива активных потоков (зеленых) образуются рваные дырки неактивных (красных)? Что касается последнего железа (Fermi), распределение работы производится на уровне warp-ов. Например, если у вас идут 32 потока активны, потом 32 неактивны, а потом снова 32 потока активны, а потом снова 32 неактивны, то всё будет хорошо (ну при условии что вы не используете явный __syncthreads() где-нибудь в коде). Активные потоки будут работать, а неактивные не будут занимать место и тратить ресурсы. Однако, на старых архитектурах (G80-GT200) менеджмент потоков всегда осуществлялся на уровне блоков. Например, если размер блока 128 потоков, и мы берем рассмотренный выше пример, то неактивные потоки будут висеть на мультипроцессоре до тех пор, пока весь блок не завершит свою работу. В случае неравномерного распределения работы для разных потоков эта проблема может стать довольно существенной. Решение этой проблемы – собственный, софтверный менеджер задач. Идею persistent threads можно в кратце выразить следующим образом:
-
1. Запустить ровно столько потоков, сколько влезет на GPU
-
2. Каждый warp делает намного больше работы, чем себя одного. То есть , когда warp завершил свою работу, он берет чужую – “воровство задач” (task stealing).
Первое реализовать не трудно, зная количество работы (то, сколько всего вы бы хотели запустить потоков, без использования persistent threads – аргумент a_size), количество используемых кернелом регистров (полагаем что разделяемая память не является ограничивающим occupancy фактором) и размер блока:
__constant__ int cm_maxThread;
static __device__ int g_warpCounter;
int CalcPersistentThreadsAndResetWarpCounter(int a_size, int regCount, int myThreadsPerBlock)
{
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, 0);
int threadBlocksPerSM = devProp.regsPerBlock/(regCount*myThreadsPerBlock);
int waprsPerSM = (threadBlocksPerSM*myThreadsPerBlock)/devProp.warpSize;
int launchedWarps = devProp.multiProcessorCount*waprsPerSM;
int launchedThreads = launchedWarps*devProp.warpSize;
int value[1] = {0};
void* g_warpCountAddress = NULL;
cudaGetSymbolAddress(&g_warpCountAddress, "g_warpCounter");
cudaMemcpy(g_warpCountAddress, value, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpyToSymbol(cm_maxThread, &a_size, sizeof(int));
return launchedThreads;
}
Использовать эту функцию следует примерно следующим образом:
int threads = CalcPersistentThreadsAndResetWarpCounter(size, 24, 192);
my_kernel<<<(threads/192), 192>>>(…);
Теперь, каждый kernel, который использует persistent threads, должен выглядеть следующим образом:
__global__ void my_kernel(…)
{
while(true)
{
__shared__ int s_nextWarpId[(BLOCK_SIZE)/32];
int& nextWarpId = s_nextWarpId[threadIdx.x/32];
if( (threadIdx.x & 0x1f) == 0)
nextWarpId = atomicAdd(&g_warpCounter, 32);
tid = nextWarpId + (threadIdx.x & 0x1f);
if(tid >= cm_maxThread)
return;
// stencil test
if(!(tex1Dfetch(stencil_tex, (tid) >> 5) & (1 << ((tid)&0x1f) )))
continue;
// my code here
//
…..
}
}
Работает это следующим образом. Когда warp завершил свою работу (например он находится в конце цикла while или был откинут стенсил-тестом), он крадет следующую порцию работы для себя, увеличивая глобальный счетчик сразу на 32. Счетчик указывает на то, сколько еще свободной работы осталось.
На G80 именно так persistent threads реализовать не получится, вследствии отсутствия атомарных операций. Но можно просто сделать цикл вида “for(int i=0;i<8;i++) doMyWork(i);” для того, чтобы увеличить количество работы, выполняемое одним warp-ом. На GT200 в некоторых случаях, использование persistent threads давало прирост производительности до 2 раз.
Тестируем Stencil
Собственно для нужд рейтрейсинга, такой стенсил буфер подошел довольно удачно. Если уткнуться в пустоту, на GTX560 возможно получается около 4 миллиардов вызов кернелов в секунду (то есть 4 миллиарда пустых вызовов в секунду). При увеличении глубины трассировки производительность практически не падала (вернее падала в соответствии с тем, насколько реально много отраженных объектов мы видим). Тесты специально производились на как можно более простой отражающей сцене и на полностью диффузной, где отражений нет вообще. На глубине трассировке >=2 все потоки неактивны. К сожалению не все кернелы в моем рейтрейсере можно было откинуть стенсилом, поэтому с ростом глубины отражений даже для диффузной сцены FPS падает. Динамика FPS следующая:
Для зеркальной сцены : 30, 25, 23.7, 20, 19.4, 18.8 (рис. 2)
Для диффузной сцены : 40, 37, 34, 32, 30, 29.5
Для сравнения, на более сложной зеркальной сцене:
Для зеркальной сцены 2: 32, 23, 18.6, 16.1, 14.4 (рис.3)

Рисунок 2. простая сцена, менее 100 треугольников.

Рисунок 3. Чуть более сложная сцена, ~ 23 тыс. примитивов. |