|
Статья опубликована в электронном журнале CGM (http://cgm.computergraphics.ru/issues/issue18/atistream)
Аннотация
Статья рассказывает о технологии STREAM, позволяющей программисту использовать видеокарты компании AMD для вычислений общего назначения. Во многом мы будем опираться на предыдущую статью, где рассказывалось про CUDA. Мы постараемся сфокусироваться на отличиях между CUDA и STREAM, а также рассмотрим особенности архитектуры RV770/RV870.
Введение
Как известно, видеокарты уже давно обходят на порядок центральные процессоры как по количеству операций с плавающей точкой в секунду, так и по пропускной способности памяти. Причина этого заключается в том, что видеокарты изначально были ориентированы на обработку массивных данных. А где много данных, там необходимы соответствующие аппаратные ресурсы. В современных компьютерных играх количество полигонов в сцене может доходить до нескольких миллионов. Растеризация производится в разрешение порядка одного мегапиксела, причем для каждого пиксела может выполняться довольно сложная программа-шейдер. Приемлемой скоростью обновления экрана считается 30-40 кадров в секунду. Таким образом, в этой области объемы обрабатываемых данных огромны. GPU – это вычислительные системы со специальной архитектурой, рассчитанные именно на массивную параллельную обработку данных.
Довольно часто можно встретить аналогию, проводимую между вычислительными машинами и транспортными средствами (рис. 1).

Рисунок 1. CPU – маленький, но быстрый. GPU – не такой быстрый, но с очень большой грузоподъемностью.
Центральному процессору (CPU) сопоставляют маленький, но быстрый мотоцикл. Видеокарта – тяжелый и медленный, но мощный грузовик, способный за раз перевозить намного больше груза, чем мотоцикл. Центральный процессор старается каждую отдельную операцию выполнить как можно быстрее. За счет этого достигается его производительность. GPU работает по другому принципу. Не важно, как быстро выполняется каждая операция по отдельности. Важно лишь чтобы вся совокупность операций в целом выполнялась быстро. Но именно различие в подходах к проектированию архитектур CPU и GPU определяет различия в принципах их программирования. Поэтому для программирования на GPU нужны специальные технологии и API, адекватно отражающие аппаратные возможности графических процессоров.
Высокопроизводительные вычисления и операции с большим количеством данных требуются в самых разных областях науки и промышленности. В связи с тем, что GPU становились все более универсальными вычислительными машинами, начали появляться технологии для программирования на них задач, не связанных с компьютерными играми и растеризацией. Среди них CUDA, Brook, DirectX11 Compute Shaders и OpenCL. STREAM – это технология для программирования задач общего назначения (General Computing on GPU - GPGPU) на видеокартах компании AMD.
Почему важно изучать STREAM?
Не секрет что STREAM из-за отставания от CUDA в прошлом, в настоящее время практически не используется. С другой стороны, существуют OpenCL и DirectX11 Compute Shaders. Может встать вопрос, зачем нужно изучать STREAM? Если важно поддерживать AMD, не лучше ли сразу перейти к OpenCL? Трудный вопрос. Дело в том, что для того, чтобы понимать, как будет работать OpenCL на видеокартах компании AMD нужно знать как устроен STREAM, так как по-видимому, OpenCL будет реализован похожим образом. Если не учитывать особенности конкретной платформы, можно сильно потерять в эффективности. Мы рассмотрим в этой статье не только сам API, но и архитектурные особенности RV770/RV870.
Термины, используемые в статье
-
Устройство (device) – видеокарта.
-
Хост (host) – программа для CPU в оперативной памяти, предназначенная для управления вычислениями.
-
SIMD ядро (SIMD Core или SIMD Engine или Мультипроцессор) – объединение из 16 потоковых процессоров, способных выполнять в одно и то же время только одну инструкцию.
-
STREAM процессор – все вычислительные ядра графической платы, то есть ее процессорная часть.
-
Ядро (kernel) – функция, выполняющаяся на GPU параллельно на множестве данных. То же самое, что kernel в CUDA.
-
CUDA – Compute Unified Device Architecture - Технология GPGPU, поддерживаемая Nvidia.
-
Wavefront – группа из 64 потоков (в архитектуре RV770/RV870).
-
PCIe memory (PCIe память) – Обычная DRAM память, доступная для шины PCI-express.
Compute Abstraction Layer (CAL)
Общая идея работы со STREAM не отличается от идеи работы с CUDA. Компания AMD предоставляет низкоуровневый интерфейс для управления запусками ядер (kernel-ов) – Compute Abstraction Layer (CAL). На CPU выполняется управляющий процесс - хост, который следит за запуском ядер. GPU код выполняется векторными мультипроцессорами (SIMD Cores). RV770/RV870 отличается от GT200 еще большей шириной инструкции, но об этом позже).
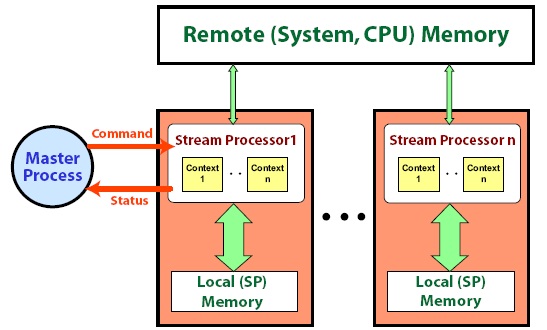
Рисунок 2. Compute Abstraction Layer
На рис. 2 изображена общая схема работы CAL. В целом, CAL – довольно низкоуровневый интерфейс, сравнимый с driver-API CUDA. Парадигма программирования та же, что и в CUDA – массивный параллелизм по данным, SPMD (Single Program Multiple Data): если мы хотим обработать массив, то надо на каждый элемент массива создать свой поток. Для описания kernel-ов используется язык Brook+. Brook+ в меньшей степени похож на C, чем то, что мы имеем в CUDA.
Модель выполнения
Единицей исполнения потоков в STREAM является wavefront. То же самое, что warp в CUDA. В архитектуре RV770/RV870 размер wavefront-а равен 64 потока [1]. В отличие от CUDA, в STREAM не обязательно объединять потоки в блоки. Это нужно только если предполагается использование разделяемой памяти. В остальном, с потоками все так же, как и в CUDA. В kernel-ах указываются входные и выходные буферы.
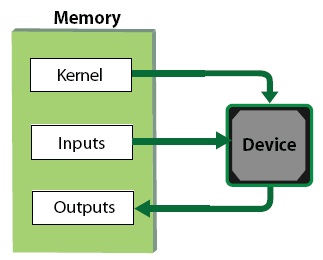
Рис. 3. Схема работы с памятью.
GPU код работает с памятью следующим образом: читает что-то из input ресурсов, считает и записывает в out ресурсы. Ресурсами в CAL называются любые буферы памяти, выделяемые для использования ядрами (kernels). Нельзя писать в input и нельзя читать из out. Не существует inout ресурсов. В этом заключается еще одно отличие от CUDA. По умолчанию также нельзя использовать один и тот же буфер как на чтение так и на запись, привязав его к двум разным ресурсам. Однако это ограничение можно обойти, если указать компилятору флаг BRT_PERMIT_READ_WRITE_ALIASING [1]. Тогда один и тот же буфер можно использовать как на чтение так и на запись следующим образом:
kernel void test(float input<>, out output<>) {
float x = input;
……
output = result;
}
test(a, a); // call from host
Имеется возможность запускать ядро (kernel) в двух режимах – одномерном и двумерном (подробнее см. тип stream). Отличие состоит в группировке потоков по wavefront-ам. В одномерном режиме первый wavefront получит потоки с индексами 0-63, второй с индексами 64-127 и.т.д. Если же ядро запущено в двумерном режиме, вся матрица потоков разбивается на блоки 8x8 и каждый wavefront – это один из блоков 8x8 [1].
Память
Память, как и в CUDA выделяется с помощью специальных функций. В STREAM различается память, выделенная под одномерные и двумерные массивы. Причем, непосредственно во время выделения память необходимо специфицировать формат массива – 8, 16, 32, 64 битные значения; 1,2 или 4-компонентный вектор [1]. С этой точки зрения, выделения памяти больше походит на создание cudaArray. Для копирования из обычной памяти в ресурсы (и обратно) используется функции calResMap и calResUnmap, которые предназначены для отображения буферов, хранящихся на GPU в буферы, находящиеся в обычной памяти CPU [1]. В STREAM из кода, выполняющегося на видеокарте (kernel-ов), можно обращаться к памяти CPU через шину PCI-express. Причем, как на чтение, так и на запись. На самом деле в CUDA тоже существует такая возможность, но в документации она не сразу бросается в глаза. Функция cudaHostAlloc() позволяет выделять “paged locked host memory”, что является аналогом remote memory в STREAM [2].
Итак, существуют три различных домена памяти, с которыми придется иметь дело в STREAM.
-
1. Host memory. Этот домен соответствует обычной DRAM память, доступной для CPU программ. GPU не имеет доступа к этой памяти.
-
2. PCIe memory. (Remote memory). Память DRAM, доступная как для CPU так и для GPU через шину PCI-express.
-
3. Local (stream processor) memory. Память видеокарты, доступна только для нее самой. К этой памяти можно обращаться только из kernel-ов.
Обмен данными между CPU и GPU может быть организован двумя способами. Первый способ - как в CUDA. Допустим, нам нужно скопировать некий массив с памяти хоста в локальную память. Мы используем calResMap/calResUnmap, не задумываясь о механизме. Функция calResUnmap фактически копирует массив сначала в PCIe память, а потом из PCI-e памяти копирует его в локальную, вызывая другую функцию calCtxCreateCopy.
Но есть еще один способ передачи данных, позволяющий избежать дополнительного копирования. Можно разместить данные сразу в памяти, доступной для шины PCI-express и вызвать функцию calCtxCreateCopy напрямую. Копирование PCIe memory => Local memory на порядок быстрее, чем host memory => PCIe memory. Поэтому возможность избежать дорогостоящего копирования очень важна. Но такая возможность дается не бесплатно. PCI-e память не кэшируется центральным процессором [1] .
Тип Stream
В первом же примере программы на STREAM мы наблюдаем загадочные переменные вида float a<10,10>. Это так называемые Stream переменные. float a<10,10> - двумерный массив в памяти GPU размером 10x10. Максимальный размер по каждому измерению – 8192 элемента. Возможны только 1D и 2D Stream массивы. Stream– уникальный тип данных. Аналога в CUDA для него не существует. Фактически, тип Stream и определяет потоки как таковые. Одной из особенностей этого типа является то, что при запуске ядра (kernel) над ним, не нужно даже указывать количество потоков. Размер Stream данных сам и определяет количество потоков.
kernel void sum(float a<>, float b<>, out float <>c)
{
c = a + b; // c[tid] = a[tid] + b[tid]. Такая индексация здесь недопустима.
}
Запускать одно ядро над Stream-ами разного размера или размерности не разрешается. Каждый поток прочитает строго свой элемент данных и никак иначе. Для копирования CPU to GPU используется команда streamRead(2); Для обратной операции – GPU to CPU – streamWrite(2);
Для идентификации потоков существуте функция instance(), которая возвращает векторный целочисленный индекс потока. Также есть операция indexof, которая возвращает тоже векторный индекс элемента Stream массива в текущем потоке, только это индекс будет с плавающей точкой. Например indexof(a).xy вернет float2, который и будет двухмерным индексом.
Gather stream = текстура
В примере с умножением матриц (в документации) 2D индексация записывается не как A[i][j] а как A[index.xy], где index – float2 переменная (да, да, еще раз – вся индексация ведется флотами). Это связано с тем, что массивы типа A[][] на самом деле являются текстурами. То есть это аналогично tex2D() в CUDA. В STREAM такие массивы называют gather stream. Отличие от CUDA заключается в том, что в STREAM в текстуры можно писать, если поставить в kernel-е квалификатор out.
Global buffer
Это аналог глобальной памяти в CUDA. Глобальный буфер можно выделить как в локальной памяти GPU так и в удаленной памяти CPU, доступной для шины PCI-e. Обращения к буферам не кэшируются.
CALformat format = CAL_FORMAT_FLOAT32_1;
CALresallocflags flag = CAL_RESALLOC_GLOBAL_BUFFER;
// Allocate 2D global remote resource
//
calResAllocRemote2D(&remoteGlobalRes, &device, 1, width, height,
format, flag);
if(!remoteGlobalRes)
{
fprintf(stdout, "Global remote resource not available on device \n");
return -1;
}
Листинг 1. Пример создания глобального буфера в удаленной памяти.
Разделяемая память (Local Data Storage - LDS)
Разделяемая память в STREAM имеет 3 принципиальных ограничения:
-
1. Элементы могут быть только 128-битными (float4).
-
2. Каждый поток может записывать только строго в свою область памяти.
-
3. Адреса, по которым производится запись, должны быть известны во время компиляции.
Прежде чем использовать разделяемую память, необходимо указать число потоков, которые хотят друг с другом взаимодействовать – то есть указать размер группы (максимальный размер группы – 1024 потока). Размер группы указывается перед объявлением kernel-а следующим образом: Attribute [Groupsize (64)]. На самом деле, группа в данном случае это прямая аналогия блоку в CUDA. Отличие в том, что в CUDA размер блока всегда обязательно указывать, а в STREAM это нужно делать, только если предполагается использовать разделяемую память.
Далее, любой поток в группе может читать из любой области разделяемой памяти, но писать может только в некоторую ему отведенную область. С этим очень тесно связан размер группы. Допустим, вы указали размер группы – 64 потока. А массив объявили из 256 элементов. Тогда нулевой поток сможет писать только в 0-3 элементы, первый в 4-7, и.т.д. Читать любой поток может из любой области LDS.
Для синхронизации внутри группы предназначена функция syncGroup(). Ее действие полностью аналогично __syncthreads() в CUDA. Эта функция выступает в роли барьера, такого что все wavefront-ы группы должны пройти его одновременно.
LDS имеет “полезную” особенность – команда _neighborExch. Данная команда быстро транспонируют матрицу 4x4. Выглядит это следующим образом: пусть каждый поток владеет 128-битным float4 вектором (xyzw). Тогда после этой операции, потоки с tid%4 == 0 получат в память все значения x от 4 следующих потоков, потоки с tid%4 == 1 получат значения y от 4 тех же самых потоков, и.т.д. Полезность этой операции, вероятно, стоит поставить под сомнение.
Разделяемые регистры
Это интересная оcобенность STREAM-а и то, чего нет в CUDA. Разделяемые регистры предназначены для того, чтобы обмениваться данными между wavefront-ами. Причем, можно распределять данные между вообще всеми wavefront-ами, даже wavefront-ами из разных групп (если используется разделяемая память). Это тот механизм, которого так не хватало многим в CUDA – разделяемые данные между блоками. С другой стороны, таким способом можно передавать данные только между теми wavefront-ами, которые в действительности одновременно исполняются на видеокарте, что вообще говоря, ставит под вопрос полезность подобного механизма.

Рисунок 4. Механизм обмена данными через разделяемые регистры.
Допустим имеется изображение 1024x1024 и необходимо реализовать некоторый фильтр шумоподавления. На каждый пиксел создаём свой поток. Вероятно, что в процессе работы алгоритма потребуется синхронизация и обмен данными между различными блоками изображения размером 8x8 (каждый такой блок будет соответствовать в точности одному wavefront-у). Однако, неизвестно какие из блоков 8x8 в действительности будут исполняться на процессоре в заданный момент времени т.к. миллион потоков одновременно видеокарта держать не сможет (все локальные данные в любом случае не поместятся в регистровый файл) а будет подкачивать их по мере необходимости. Поэтому реализовать с помощью разделяемых регистров адекватное взаимодействие между блоками нетривиально.
Локальная память
Локальной памятью в STREAM называется обычная DRAM память, расположенная непосредственно на видеокарте – то, что в CUDA называют глобальной памятью. Локальная память выделяется с помощью команд calResAllocLocal1D и calResAllocLocal2D. Причем, различается обычная локальная память и так называемый глобальный буфер. Обращения к обычной локальной памяти кэшируются, к глобальному буферу – нет. Чтобы выделить глобальный буфер, нужно указывать ф-ям calResAllocLocal1D и calResAllocLocal2D флаг CAL_RESALLOC_GLOBAL_BUFFER. Глобальный буфер также можно выделить и в удаленной памяти, указав тот же самый флаг функциям calResAllocRemote1D и calResAllocRemote2D (с.м. дальше).
Удаленная память (remote memory, PCIe memory)
STREAM процессор может обращаться к памяти на хосте. Доступ осуществляется через шину PCI-express и он, конечно, медленнее, чем доступ к локальной GPU памяти. Remote память выделяется с помощью команд calResAllocRemote1D и calResAllocRemote2D. Следует отметить, что для ядра нет разницы, где расположена память. Код самого ядра от этого не изменяется. И с локальной и с удаленной памятью, с точки зрения программиста, работа ведется одинаково. Удаленная память обычно используется для обмена данными между разными GPU (если их в системе несколько).
ВНИМАНИЕ: Удаленная память не кэшируется центральным процессором
Иногда может возникать такая ситуация, когда данные надо обрабатывать на CPU. Чтобы CPU мог быстро обрабатывать данные, ему нужно их кэшировать. Оказывается, что удаленная память, хоть и доступна для CPU, но не кэшируется. Для того, чтобы память кэшировалась, ее необходимо выделять с флагом CAL_REALLOC_CACHEABLE у команд calResAllocRemote*D (где * это 1 или 2) или с помощью malloc/new. Но это палка о двух концах: кэшируемая память недоступна для работы с устройства (видеокарты). Удаленная память с флагом CAL_REALLOC_CACHEABLE может быть все же полезна, но для другой цели – для быстрого копирования в GPU память с помощью функции calCtxCreateCopy.
Константная память
Константной памяти в Brook+ по-видимому нет. Поддержка константной памяти обещается в следующих версиях STREAM. В STREAM Intermediate Language и ассемблере 6xx/7xx/8xx константная память есть [3].
Stream процессор и архитектура RV770/RV870
Процессоры RV770 и RV870 имеет невероятно сложную систему команд. Это связано во-первых отчасти с тем, что вычислительные ядра векторные. А от части с тем, ATI и впоследствии AMD придерживаются строго VLIW архитектуры.
VLIW (англ. Very large instruction word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами. Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно. Листинг 2 демонстрирует отличие VLIW команд от SIMD. В ассемблере RV770/RV810 одна команда состоит из 5 инструкций для каждого из вычислительных юнитов x,y,z,w и t (рис. 7).
SIMD команда:
x: MUL R0.x, R1.x, KC0[1].x
y: MUL R0.y, R1.y, KC0[1].y
z: MUL R0.z, R1.z, KC0[1].z
w: MUL R0.w, R1.w, KC0[1].w
t: MUL R0.t, R1.t, KC0[1].t
VLIW команда:
x: MUL R0.x, R1.x, KC0[1].x
y: LSHR T1.y, R1.y, KC0[1].y
z: SUB T1.z, R1.z, KC0[1].z
w: MOV R0.w, R1.w
t: MOV R0.t, R1.t
Листинг 2. Пример ассемблера RV770/RV870 [4].
SIMD команда позволяет выполнить набор одинаковых операций над разными данными. В то же время характерной чертой VLIW является запаковка разных операций в одной команде.
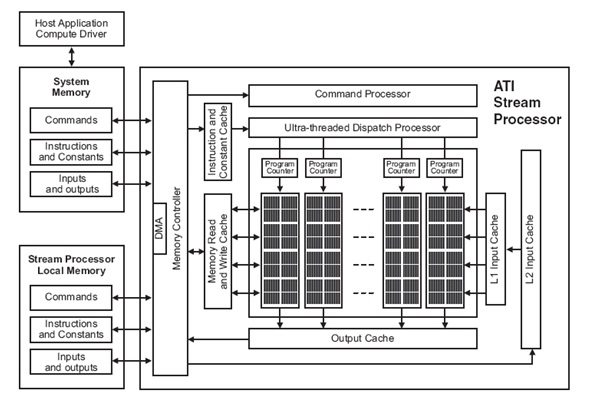
Рисунок 5. Архитектура STREAM процессора.
Рассмотрим устройство STREAM процессора (рис. 3). Какую полезную информацию можно извлечь из этой картинки? Во-первых, в глаза бросается множество различных КЭШей. Это определенно хорошо, однако подробности их работы AMD не раскрывает. Во-вторых, следует обратить внимание на специальный блок – DMA контроллер. Он позволяет обращаться к системной памяти через шину PCI-express параллельно с обращениями к локальной памяти. Ядро STREAM процессора состоит из объединений, называемых SIMD Engine или SIMD Core.
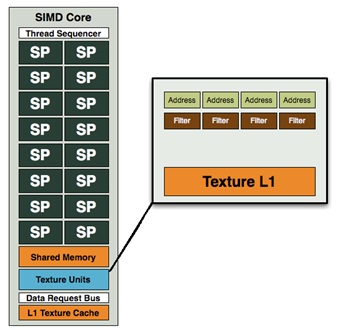
Рис. 6. SIMD Сore (или SIMD Engine).
SIMD Core выполняет на всех своих потоковых процессорах (SP – Streaming Processor) одну и ту же инструкцию. Причем, архитектура потоковых процессоров векторная (рис. 5).
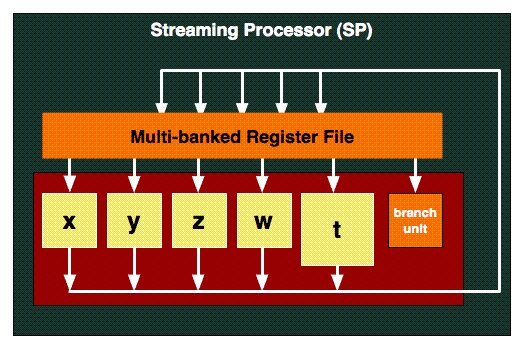
Рис. 7. Устройство потокового процессора в RV770/RV870.
Каждая инструкция может содержать до 5 разных (VLIW архитектура) операций одновременна. Но для того, чтобы этот механизм работал, необходимо чтобы все 5 операций принадлежали к одному потоку, поэтому нужно писать такой код, который компилятор смог бы векторизовать и эффективно запаковать во VLIW инструкцию. Из этой архитектуры вытекает, что RV770/RV870 хорошо справляется с тяжелым, векторным кодом. Достаточно рассмотреть оптимизированный пример умножения матриц, приведенный в документации по STREAM.

Рис. 8. Фрагмент кода оптимизированного для RV770/RV870 умножения матриц. Всего аккумуляторов 8 штук.
В целом, широкий wavefront в сочетании с векторными процессорами дает… 64*5 = 320 операций с плавающей точкой операций в одной команде. Реально инструкции будут выполняться не все параллельно, а по 16*5, но для программиста разницы нет, так как размер wavefront-а равен 64.
Литература
|