|
На GPU быстрый рейтрейсинг сделать на самом деле сложнее чем на CPU, несмотря на чистый выигрыш GPU по гигафлопсам. Специфическая архитектура и технологии создания ПО для GPU порождают ряд проблем.
Основные трудность трассировки лучей на GPU
Вы думали, самая главная проблема это отсутствие стека? - не угадали. Отсутствие стека конечно больно бьет по разработчику, но эта проблема решается. Если вы разрабатываете программу например на CUDA, стек элементарно строится на локальной памяти. Он конечно будет не очень быстрым, но во многих случаях скорость его работы удовлетворительна. На самом деле это конечно проблема, но не первичная. Прежде, чем разработка упрется в то, что стека нет и поэтому трудно реализоывать эффективный distributed ray tracing например, стоит решить другую проблему.
Попытка номер 2. Основная проблема трассировки лучей - это высокая латентность памяти? Уже ближе, но все-равно неверно. Латентность конечно высокая и нагрузка на память значительная (особенно на текстурные блоки во время поиска в kd дереве), но не надо забывать о высокой пропускной способности памяти GPU и о текстурных кэшах. Латентность можно эффективно скрывать за счет параллельности. Если занятость мультипроцессора высока, память может и не являться камнем предкновения. Итак, на самом деле, при сегодняшних GPU (2012) год, проблем существует несколько.
Нехватка регистров
Обдна из проблемм проблема трассировки лучей на GPU в том, что для алгоритма не хватает регистров графического процессора. Не хватает не в том смысле, что их впринципе нет, а в том, что для эффективной реализации ядро (или шейдер) должны занимать как можно меньше регистров, чтобы занятость (occupancy) мультипроцессоров была высокой. Таблицы 1 и 2 могут быть легко получены с помощью CUDA Occupancy calculator. Параметр размер блока может имень на самом деле несколько разных значений при которых будет достигаться оптимальная занятость.
|
Кол-во регистров |
размер блока |
занятость |
| 10 |
192 |
100% |
| 16 |
64 |
67% |
| 20 |
192 |
50% |
| 32 |
64 |
33% |
Таблица 1. Некоторые комбинации для G80.
В GT200 увеличен так называемый регистровый файл, так что ситуация выглядит получше.
|
Кол-во регистров |
размер блока |
занятость |
| 10 |
256 |
100% |
| 16 |
256 |
100% |
| 20 |
192 |
75% |
| 32 |
64 |
50% |
Таблица 2. Некоторые комбинации для GT200.
Теперь возмем для примера код пересечения луча и треугольника. Вернее, рассмотрим формулы, по которым это пересечение рассчитывается. На рисунке t1 соответствуте t в формуле.
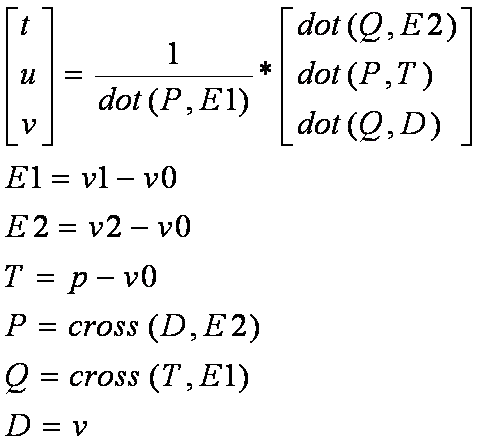 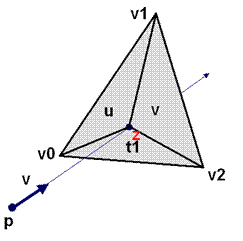
Рисунок 1. пересечение луча и треугольника, формулы.
Итак, у нас есть сам треугольник - 3 вершины по 3 float - это 9 регистров. Есть луч - это 6 регистров. И теперь еще надо добавить некоторые промежуточные переменные - те что в формулах и мелочи - идентификатор потока, счетчик цикла по треугольникам и проч, что может понанобиться. Получается, что даже в теории одно только пересечение луча и треугольника занимает больше 20 регистров. То есть мы уже не попадаем в наиболее эффективный диапазон как для G80 так для и GT200. Более того, помимо подсчета пересечений нужно делать еще очень много вещей - траверсить ускоряющие структуры, делать шейдинг, генерить новые лучи - теневые, отраженные, преломленные. А регистров уже нет. Выходя за определенную черту занятости, вы вынужнаете компилятор помещать часть данных в локальную память, что дополнительно увеличивает нагрузку на шину.
Ветвления
Вторая, очень значимая проблемма - это огромное количество ветвлений в коде. Не только в коде траверса дерева. Но и в остальных местах - шейдинг, вычисление отраженных лучей и прочее. Чем более сложную модель материала вы реализуете, тем больше ветвлений будет в коде. Чем более сложный алгоритм (трассировка лучей сама по себе или path tracing). Чем более сложные источники света...и.т.д. Компилятор почти всегда старается преобразовать код в простую последовательность команд, заменяя все условные операторы на операции compare-move.
Дивергентные обращения в память
С этим очень сложно бороться. Есть несколько работ (особенно следует обратить вниманию на работы Кирилла Гаранжи), где лучи сортируются для формирования более когерентных групп. Однако, этот подход довольно сложен, требует дополнительной памяти, усложняет весь конвейер и далеко не каждый разработчик им пойдет. Иногда лучше сохранить простоту алгоритма, чем выжимать пусть даже и значимые проценты производительности, рискуя при этом получить несопровождаемый код.
Заключение
Просто рейтрейсинг на GPU реализовать не очень сложно. Проблеммы начинаются тогда, когда нужно с помощью рейтрейсинга делать что-то нетривиальное, например считать global illumination для сцен со сложными свойсвами материалов. |